As an aside exercise for my digital history class, we were asked to read a paper by Alan Cooper called "Your Program's Posture." Cooper categorizes programs as sovereign, transient, daemonic, or parasitic, the specific classification depending on how it interacts with the user, and the assignment asked us to consider where the programs we use in the course of our work lie in that grouping. I already had a good idea of where the software I use would lie, but I also felt I should read the article before going with my gut instinct of classifying everything as daemonic.
Cooper's categories are described in terms of "postures," essentially their dominant "style" or gross characteristics which determine how users approach, use, and react to them. The first of these four postures is the "sovereign" posture: sovereign programs are paramount to the user, filling most or all of the screen's real estate and functioning as the core of a given project.
The second is "transient," and is the opposite of sovereign software both visually and in terms of interfaces. Intended for specific purposes, meant to be up only temporarily (or, if up for a long time, not constantly interacted with), transient programs can get away with being more exuberant and less intuitive than sovereign applications.
I realized my gut reaction of describing half the annoying stuff I use as daemonic when I realized that the third posture refers to daemon in the computing sense of the word rather than the more traditional gaggle of evil critters with cool names. (Computing jargon tends to come from the oddest places.) Daemonic postures are subtle ones, running constantly in the background but not necessarily being visible to the user at any given time. Daemonic programs tend to either have no interface (for all practical purposes) or tend to have very minimal ones, as the user tends not to do much with them, if anything. They're usually invisible, like printer drivers or the two dozen or so processes a typical computer has running at any time.
The final set of programs are called "parasitic" ones, in the sense that they tend to park on top of another program to fulfill a given function. Cooper describes them as a mixture of sovereign and transient in that they tend to be around all the time, but running in the background, supplementary to a sovereign program. Clocks, resource meters, and so on, generally qualify.
In the interest of this not being entirely a CS post, I should probably answer the initial request on the syllabus as to how it can affect my historical research process. I'm not sure, fully, but I'm also answering this entirely on the fly and and more concerned with how it should affect my process. At present, I'm not using many programs specifically for research purposes. Firefox and OpenOffice (which I use en lieu of Microsoft Office, moreso since that hideous new interface in Office '07 began to give me soul cancer), the main programs I tend to have up at any given time and which I obviously do a lot of my work in, are definitely sovereign program, taking up most of my screen's real estate. The closest thing I have to a work-related application that's transient is Winamp, which is usually parked in the semi-background cheerfully producing background noise I need to function properly. I don't make much use of parasitic programs due to a lack of knowledge of the options about them, mainly, and of course my daemonic ones are usually invisible.
The chunks of this I make use of are mostly a case of "if it ain't broke, don't fix it." I've got my browser, through which I access a lot of my research tools (including Zotero, the most obvious parasitic application I have, and the aggregator functions of Bloglines, the, uh, other most obvious parasitic application I have); I've got my word processor, through which I process my words; I've got Photoshop for 2D graphics work and hogging system resources; I've got Blender for 3D graphics stuff (much though I am annoyed by its coder-designed interface); I've got FreeMind, which is great for planning stuff out. I've no shortage of big, screen-eating sovereign applications, in other words, most of which do their often highly varied jobs quite well.
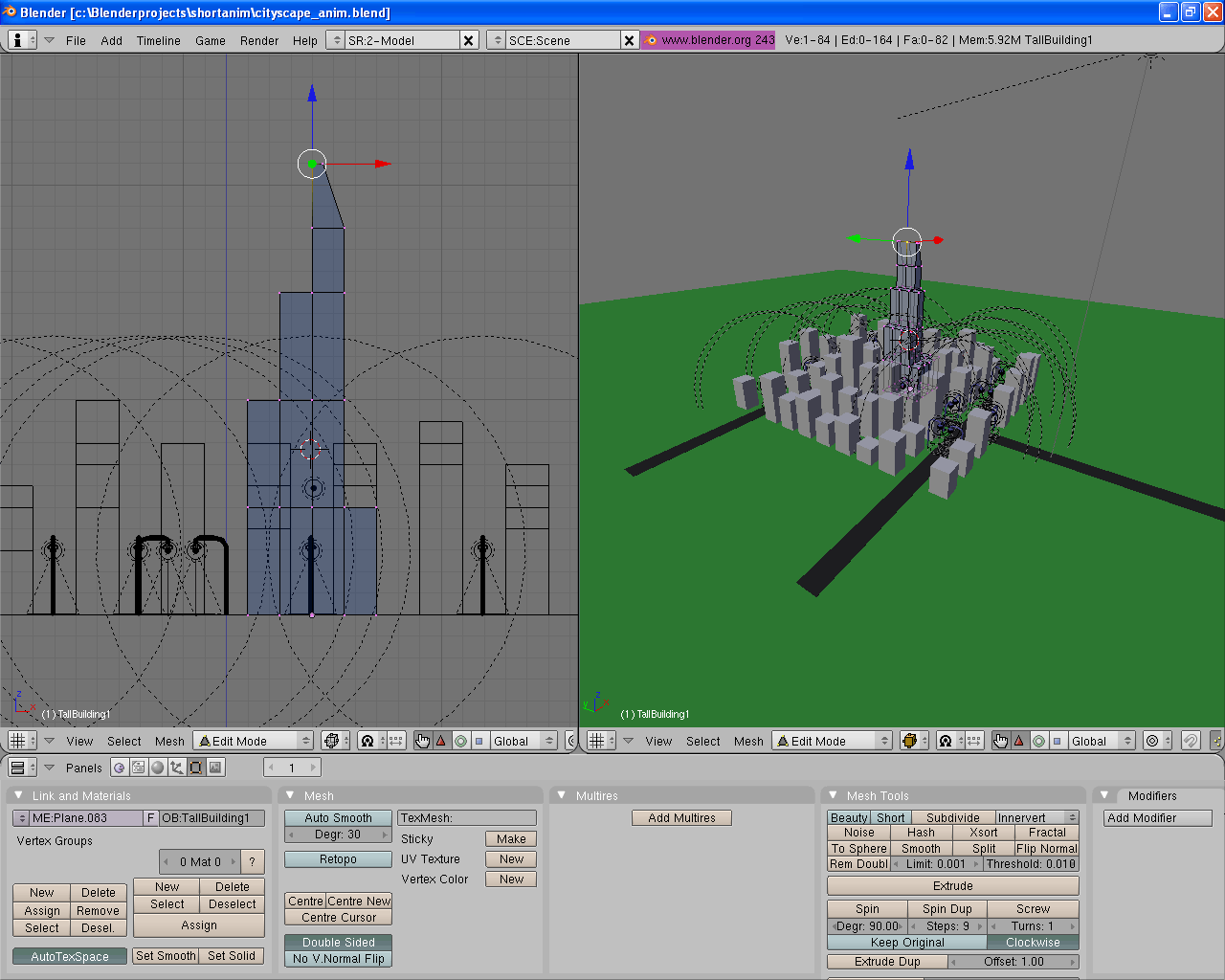
Some of these can wander from one form to another, of course. I spent an hour earlier this evening working with Blender's animation function to produce a short CG video. When I started the program rendering the six hundred frames of that video, I wasn't going to be doing anything else with it for awhile, and was thus able to simply shunt it out of the way. That left me with a small window showing the rendering process in one corner of my screen, allowing me to work in some other stuff, albeit slightly more slowly as the computer chundered away. Cast down from the throne, the sovereign program became transitorily transient.
What I'm wondering about now, though, are applications which fill the other two postures; stuff that you can set up and just let fly to assist with research or other purposes. An simple and obvious example of this sort of thing would be applications which can trawl RSS feeds for their user. Some careful use setting the application up in the first place - search, like research, is something which can occasionally take significant skill to get useful results - and you could kick back (or deal with more immediate or physical research and other issues) and allow your application to sift thousands of other documents for things you're interested in. Things like this are not without their flaws - unless you're a wizard with searches or otherwise incredibly fortunate, you're as likely as not to miss quite a bit of stuff when trawling fifty or five hundred or five thousand feeds. Then again, that's going to happen anyway no matter what you're researching in this day and age, and systems like this would greatly facilitate at least surveying vast bases of information that would otherwise take up scores of undergraduate research assistants to get through.
The information is out there; there just need to be some better tools (or better-known tools) to dig through it. Properly done, something like this would need minimal interaction once it gets going; you set it up, tell it to trawl your feeds (or Amazon's new books sections, or H-Net's vast mailing lists, or more specialized databases for one thing or another, etc.), and only need to check back in daily or weekly or whenever your search application beeps or blinks or sets off a road flare, leaving you to spend more of your attention on whatever else may need doing. Going through the results would still involve some old-fashioned manual sifting, as likely as not, but if executed properly you would be far more likely to come up with some interesting results than you would by sifting through a tithe of the information in twice the time.
Something like this could help get data from more out-of-left-field areas, as well; setting up a search aggregator as an historian and siccing it, with the terms of whatever you're interested in, on another field like economics or anthropology or law or botany or physics might be a bit of a crapshoot, but could well also yield some surprising views on your current topic from altogether different perspectives, or bring in new tools or methods that the guys across campus thought of first (and vice versa). That sort of collision is what resulted in classes like this (or, at a broader level, public history in general), of course. I want to see more of that - much more.
It could be interesting to see what kind of mashups would result if people in history and various other fields began taking a more active stance on that sort of thing. Being able to look over other disciplines' shoulders is one of those things that simply can't hurt - especially if we have the tools to do so more easily than we could in the past.
I meant to segue into daemonic applications by talking some about distributed computing research, as much to see if I could find ways to drag history into that particularly awesome and subtle area of knowledge, but as usual my muse has gotten away from me and forced a tome onto your screen. So I do believe I shall keep that for some other time...
{kind=link}
Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment